Why a Model Is Better than Raw Data
When we think about raw data and a model based on that data, it might be tempting to think that the actual data is better. I mean, a model is just an approximation of the distribution or behavior found in the data, right? Technically, yes, but let’s think about that a bit more.
First, let’s take a look at some raw dummy data:
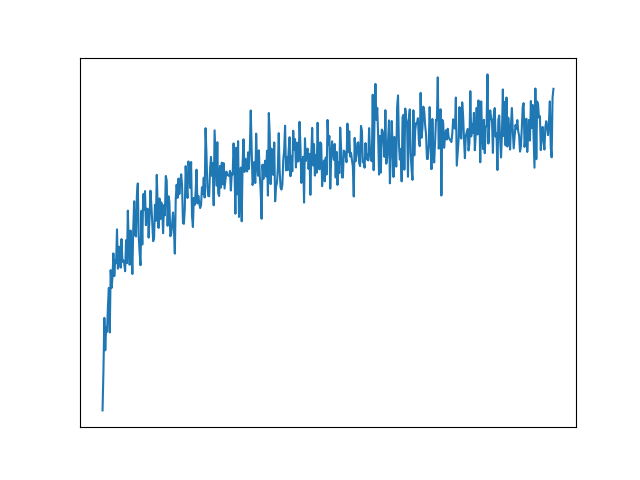
We can definitely see some kind of trend there. But are we really interested in all the spikes in the data? Individual data points are not that important. Instead, let’s see what the underlying model could look like:
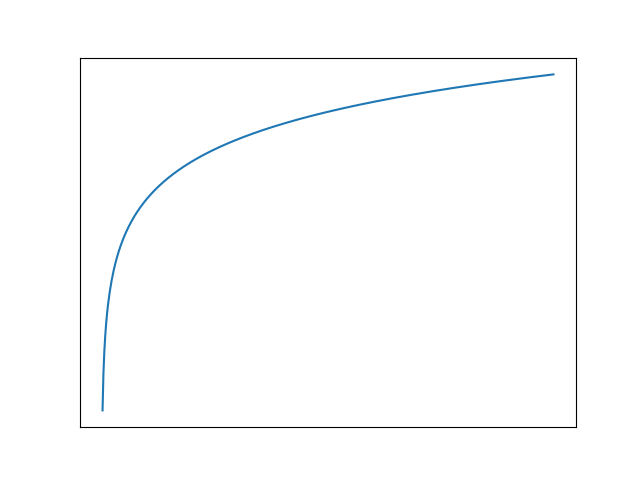
Even when looking at the raw data figure, the model above is actually what we are wanting to see. It’s basically the overall trend without the noise.
Of course, how we get the model and how it can be visualized is a different matter. The practicality of any model depends on how accurate it is (among other things). But on a general level we can say that a good model gives us more information than raw noisy data.